Algorithms
This page describes the development of the algorithm that is used in Routino for finding routes.Simplest Algorithm
The algorithm to find a route is fundamentally simple: Start at the beginning, follow all possible routes and keep going until you reach the end.While this method does work, it isn't fast. To be able to find a route quickly needs a different algorithm, one that can find the correct answer without wasting time on routes that lead nowhere.
Improved Algorithm
The simplest way to do this is to follow all possible segments from the starting node to the next nearest node (an intermediate node in the complete journey). For each node that is reached store the shortest route from the starting node and the length of that route. The list of intermediate nodes needs to be maintained in order of shortest overall route on the assumption that there is a straight line route from here to the end node.At each point the intermediate node that has the shortest potential overall journey time is processed before any other node. From the first node in the list follow all possible segments and place the newly discovered nodes into the same list ordered in the same way. This will tend to constrain the list of nodes examined to be the ones that are between the start and end nodes. If at any point you reach a node that has already been reached by a longer route then you can discard that route since the newly discovered route is shorter. Conversely if the previously discovered route is shorter then discard the new route.
At some point the end node will be reached and then any routes with potential lengths longer than this actual route can be immediately discarded. The few remaining potential routes must be continued until they are found to be shorter or have no possibility of being shorter. The shortest possible route is then found.
At all times when looking at a node only those segments that are possible by the chosen means of transport are followed. This allows the type of transport to be handled easily. When finding the quickest route the same rules apply except that the criterion for sorting is the shortest potential route (assuming that from each node to the end is the fastest possible type of highway).
This method also works, but again it isn't very fast. The problem is that the complexity is proportional to the number of nodes or segments in all routes examined between the start and end nodes. Maintaining the list of intermediate nodes in order is the most complex part.
Final Algorithm
The final algorithm that is implemented in the router is basically the one above but with an important difference. Instead of finding a long route among a data set of 8,000,000 nodes (number of highway nodes in UK at beginning of 2010) it finds one long route in a data set of 1,000,000 nodes and a few hundred very short routes in the full data set. Since the time taken to find a route is proportional to the number of nodes that need to be considered the main route takes 1/10th of the time and the very short routes take almost no time at all.The solution to making the algorithm fast is therefore to discard most of the nodes and only keep the interesting ones. In this case a node is deemed to be interesting if it is the junction of three or more segments or the junction of two segments with different properties or has a routing restriction different from the connecting segments. In the algorithm and following description these are classed as super-nodes. Starting at each super-node a super-segment is generated that finishes on another super-node and contains the shortest path along segments with identical properties (and these properties are inherited by the super-segment). The point of choosing the shortest route is that since all segments considered have identical properties they will be treated identically when properties are taken into account. This decision making process can be repeated until the only the most important and interesting nodes remain.
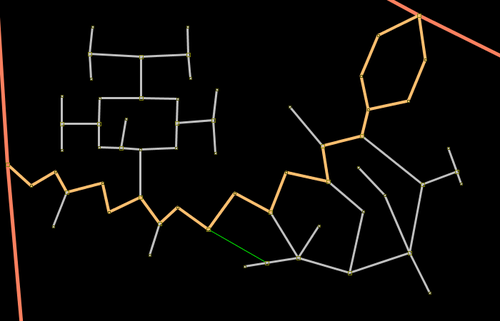
Original Highways
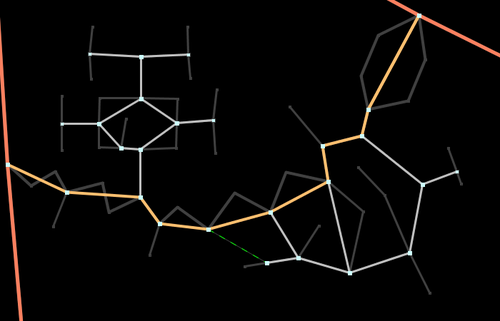
First Iteration
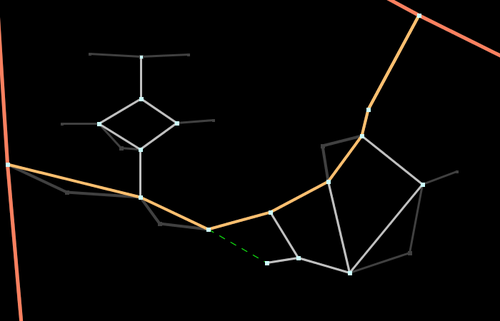
Second Iteration
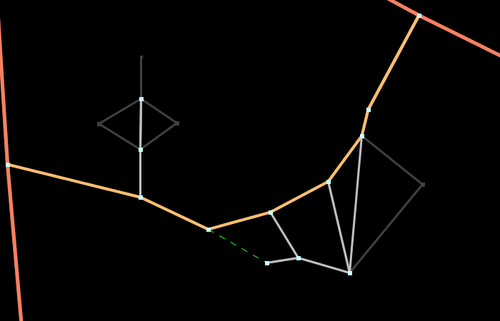
Third Iteration
Fourth Iteration
To find a route between a start and finish point now comprises the following steps (assuming a shortest route is required):
- Find all shortest routes from the start point along normal segments and stopping when super-nodes are reached.
- Find all shortest routes from the end point backwards along normal segments and stopping when super-nodes are reached.
- Find the shortest route along super-segments from the set of super-nodes in step 1 to the set of super-nodes in step 2 (taking into account the lengths found in steps 1 and 2 between the start/finish super-nodes and the ultimate start/finish point).
- For each super-segment in step 3 find the shortest route between the two end-point super-nodes.
When the first route reaches the final node the length of that route is retained as a benchmark. Any shorter complete route that is calculated later would replace this benchmark. As routes are tested any partial routes that are longer than the benchmark can be immediately discarded. Other partial routes have the length of a perfect straight highway to the final node added to them and if the total exceeds the benchmark they can also be discarded. Very quickly the number of possible routes is reduced until the absolute shortest is found.
For routes that do not start or finish on a node in the original data set a fake node is added to an existing segment. This requires special handling in the algorithm but it gives mode flexibility for the start, finish and intermediate points in a route.
Algorithm Evolution
In Routino versions 1.0 to 1.4 the algorithm used to select a super-node was the same as above except that node properties were not included. Routino versions 1.4.1 to 1.5.1 used a slightly different algorithm which only chose nodes that were junctions between segments with different properties (or has a routing restriction that is different from connecting segments in versions 1.5 and 1.5.1). The addition of turn restrictions (described in more detail below) requires the original algorithm since the super-segments more accurately reflect the underlying topology.Routing Preferences
One of the important features of Routino is the ability to select a route that is optimum for a set of criteria such as preferences for each type of highway, speed limits and other restrictions and highway properties.All of these features are handled by assigning a score to each segment while calculating the route and trying to minimise the score rather than simply minimising the length.
- Segment length
- When calculating the shortest route the length of the segment is the starting point for the score.
- Speed preference
- When calculating the quickest route the time taken calculated from the length of the segment and the lower of the highway's own speed limit and the user's speed preference for the type of highway is the starting point for the score.
- One-way restriction
- If a highway has the one-way property in the opposite direction to the desired travel and the user's preference is to obey one-way restrictions then the segment is ignored.
- Weight, height, width & length limits
- If a highway has one of these limits and its value is less than the user's specified requirement then the segment is ignored.
- Highway preference
- The highway preference specified by the user is a percentage, these are scaled so that the most preferred highway type has a weighted preference of 1.0 (0% always has a weighted preference of 0.0). The calculated score for a segment is divided by this weighted preference.
- Highway properties
- The other highway properties are specified by the user as a percentage and each highway either has that property or not. The user's property preference is scaled into the range 0.0 (for 0%) to 1.0 (for 100%) to give a weighted preference, a second "non-property" weighted preference is calculated in the same way after subtracting the user's preference from 100%. If a segment has a particular property then the calculated score is divided by the weighted preference for that property, if not then it is divided by the non-property weighted preference. A non-linear transformation is applied so that changing property preferences close to 50% do not cause large variations in routes.
Data Pruning
From version 2.2 there are options to "prune" nodes and segments from the input data which means to remove nodes and/or segments without significantly changing the routing results.The pruning options must meet a number of conditions to be useful:
- The topology relevant to routing must remain unchanged. The instructions that are produced from the reduced set of nodes and segments must be sufficiently accurate for anybody trying to follow them on the ground.
- Any restrictions belonging to nodes or segments that stop certain types of traffic from following a particular highway must be preserved.
- The total length must be calculated using the original data and not the simplified data which by its nature will typically be shorter.
- The location of the remaining nodes and segments must be a good representation of the original nodes and segments. Since the calculated route may be displayed on a map the remaining nodes and segments must clearly indicate the route to take.
The prune options all have user-controllable parameters which allow the geographical accuracy to be controlled. This means that although the topology is the same the geographical accuracy can be sacrificed slightly to minimise the number of nodes and segments.
The pruning options that are available are:
- Removing the access permissions for a transport type from segments if it is not possible to route that transport type from those segments to a significant number of other places. The limit on the pruning is set by the total length of the isolated group of segments. This significantly increases the chance that a route will be found by not putting waypoints in inaccessible places.
- Removing short segments, the limit is set by the length of the segment. This removes a number of redundant segments (and associated nodes) but rules are applied to ensure that removing the segments does not alter junction topology or remove node access permissions or changes in way properties.
- Removing nodes from almost straight highways, the limit is set by the distance between the remaining segments and the original nodes. This removes a large number of redundant nodes (and therefore segments) but again care is taken not to remove node access permissions or changes in way properties.
Turn Restrictions
The addition of turn restrictions in version 2.0 adds a set of further complications because it introduces a set of constraints that are far more complex than one-way streets.A turn restriction in the simplest case is a combination of a segment, node and segment such that routes are not allowed to go from the first segment to the second one through the specified node. Exceptions for certain types of traffic can also be specified. Currently only this simplest type of turn restriction is handled by the algorithm.
The first complication of turn restrictions is that the algorithm above requires that super-segments are composed of segments with identical properties. A turn restriction is not the same in both directions so a super-segment cannot include any route through that turn restriction. The node at the centre of the turn restriction must therefore be a super-node to avoid this. In addition to this all nodes connected to the turn restriction node by a single segment must also be super-nodes to avoid any long-distance super-segments starting at the restricted node.
The second complication of a turn restriction is that the optimum route may require passing through the same node more than once. This can happen where the route needs to work around a turn restriction by driving past it, turning round (on a roundabout perhaps) and coming back along the same highway. Without turn restrictions a route could be defined purely by the set of nodes that were passed; no node would exist more than once along a route between two points. With turn restrictions the route is defined by a node and the segment used to get there; no route between two points will ever need to follow the same segment in the same direction more than once.
A side-effect of this is that a route that works around a turn restriction must be calculable using the super-segments that are stored in the database. This puts a limit on the amount of database optimisation that can be performed because if too many super-segments are removed the optimum work-around may also be removed. The solution to this is to ensure that the database preserves all loops that can be used to turn around and reverse direction, previously super-segments that started and finished on the same super-node were disallowed.
Another side-effect of having the route composed of a set of locations (nodes) as well as the direction of travel (segments used to reach them) is that via points in the route can be forced to continue in the original direction. If the chosen method of transport obeys turn restrictions then it will not reverse direction at a via point but will find an optimum route continuing in the same direction. The only exception to this is when the route ahead at a waypoint is into a dead-end and an immediate U-turn is allowed.
A side-effect of having the starting direction at a via point defined by the previous part of the route is that overall non-optimal routes may be found even though each section between via points is optimal. For a route with a start, middle and end point defined it can be the case that the shortest route from the start to the middle arrives in the opposite direction to that required for the optimal route from the middle to the end. The calculation of the route in separate sections therefore may give a non-optimum result even though each section is itself optimum based on the start conditions.
Overall the presence of turn restrictions in the database makes the routing slower even for regions of the map that have no turn restrictions.
Data Implementation
The hardest part of implementing this router is the data organisation. The arrangement of the data to minimise the number of operations required to follow a route from one node to another is much harder than designing the algorithm itself.The final implementation uses a separate table for nodes, segments and ways. Each table individually is implemented as a C-language data structure that is written to disk by a program which parses the OpenStreetMap XML data file. In the router these data structures are memory mapped so that the operating system handles the problems of loading the needed data blocks from disk.
Each node contains a latitude and longitude and they are sorted geographically
so that converting a latitude and longitude coordinate to a node is fast as well
as looking up the coordinate of a node. The node also contains the location in
the array of segments for the first segment that uses that node.
Each segment contains the location of the two nodes as well as the way that the
segment came from. The location of the next segment that uses one of the two
nodes is also stored; the next segment for the other node is the following one
in the array. The length of the segment is also pre-computed and stored.
Each way has a name, a highway type, a list of allowed types of traffic, a speed
limit, any weight, height, width or length restrictions and the highway
properties.
The super-nodes are mixed in with the nodes and the super-segments are mixed in with the segments. For the nodes they are the same as the normal nodes, so just a flag is needed to indicate that they are super. The super-segments are in addition to the normal segments so they increase the database size (by about 10%) and are also marked with a flag. Some segments are therefore flagged as both normal segments and super-segments if they both have the same end nodes.
The relations are stored separately from the nodes, segments and ways. For the turn restriction relations the initial and final segments are stored along with the restricted node itself. Each node that has a turn restriction is marked in the main node storage with a flag to indicate this information.